
因为利用大模型的能力搭建知识库本身就是一个RAG技术的应用。
所以在进行本地知识库的搭建实操之前,我们需要先对RAG有一个大概的了解。
以下内容会有些干,我会尽量用通俗易懂的描述进行讲解。
我们都知道大模型的训练数据是有截止日期的,那当我们需要依靠不包含在大模型训练集中的数据时,我们该怎么做呢?实现这一点的主要方法就是通过检索增强生成RAG(Retrieval Augmented Generation)。
在这个过程中,首先检索外部数据,然后在生成步骤中将这些数据传递给LLM。
我们可以将一个RAG的应用抽象为下图的5个过程:
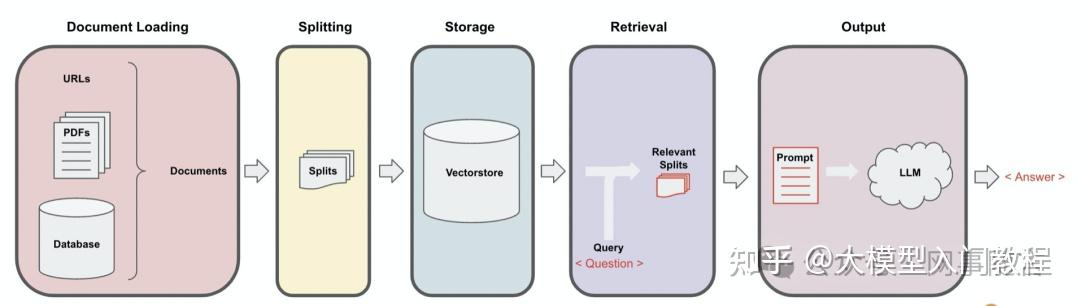
- 文档加载(Document Loading):从多种不同来源加载文档。LangChain提供了100多种不同的文档加载器,包括PDF在内的非结构化的数据、SQL在内的结构化的数据,以及Python、Java之类的代码等
- 文本分割(Splitting):文本分割器把Documents 切分为指定大小的块,我把它们称为“文档块”或者“文档片”
- 存储(Storage):存储涉及到两个环节,分别是: 将切分好的文档块进行嵌入(Embedding)转换成向量的形式 将Embedding后的向量数据存储到向量数据库
- 检索(Retrieval):一旦数据进入向量数据库,我们仍然需要将数据检索出来,我们会通过某种检索算法找到与输入问题相似的嵌入片
- Output(输出):把问题以及检索出来的嵌入片一起提交给LLM,LLM会通过问题和检索出来的提示一起来生成更加合理的答案
文本加载器(Document Loaders) 文本加载器就是将用户提供的文本加载到内存中,便于进行后续的处理
文本切割器(Text Splitters) 文本分割器把Documents 切分为指定大小的块,我把它们称为“文档块”或者“文档片”
文本切割通常有以下几个原因
为了更好的进行文本嵌入以及向量数据库的存储 通常大语言模型都有上下文的限制,如果不进行切割,文本在传递给大模型的时候可能超出上下文限制导致大模型随机丢失信息 文本切割器的概念是非常容易理解的,这里我们简单了解下文本切割器的工作流程
将文本切割成小的,语义上有意义的块(通常是句子) 开始将这些小块组成一个较大的块,直到达到某个块的大小(这个会通过某种函数测量) 一旦达到该大小,就将该块作为自己的文本片段,并开始创建一个新的文本块,同时保留一些重叠(以保持块之间的上下文)。 文本嵌入模型(Text Embedding models) 文本嵌入模型是用来将文本转换成数值向量的工具,这些向量能够捕捉文本的语义信息,使得相似的文本在向量空间中彼此接近。这对于各种自然语言处理任务,如文本相似性比较、聚类和检索等,都是非常有用的。下面是一段对嵌入的解释
词嵌入(Word Embedding)是自然语言处理和机器学习中的一个概念,它将文字或词语转换为一系列数字,通常是一个向量。简单地说,词嵌入就是一个为每个词分配的数字列表。这些数字不是随机的,而是捕获了这个词的含义和它在文本中的上下文。因此,语义上相似或相关的词在这个数字空间中会比较接近。
举个例子,通过某种词嵌入技术,我们可能会得到:
“国王” -> [1.2, 0.5, 3.1, …] “皇帝” -> [1.3, 0.6, 2.9, …] “苹果” -> [0.9, -1.2, 0.3, …]
从这些向量中,我们可以看到“国王”和“皇帝”这两个词的向量在某种程度上是相似的,而与“苹果”这个词相比,它们的向量则相差很大,因为这两个概念在语义上是不同的。
词嵌入的优点是,它提供了一种将文本数据转化为计算机可以理解和处理的形式,同时保留了词语之间的语义关系。这在许多自然语言处理任务中都是非常有用的,比如文本分类、机器翻译和情感分析等。