
语音交互是AI最重要的领域之一,也是目前落地产品比较成熟的领域,比如说智能客服、智能音箱、聊天机器人等,都已经有成熟的产品了。语音交互主要由哪些部分组成?各自主要处理什么任务?目前都遇到什么困难?本文将跟大家一起探讨下。
1 语音交互的组成
我们以一个智能音箱的例子来开始今天的讨论:
假设我们对智能音箱天猫精灵说“放一首周杰伦的《晴天》”。天猫精灵就会说“好的,马上为你播放周杰伦的《晴天》”,并且开始播放音乐。
这个过程猫精灵都做了些什么?
首先,天猫精灵把听到的声音转化成文字,然后理解内容,最后做出相应策略,并把响应策略转化成语音。
因此,语音交互就可以成以下这三个模块:
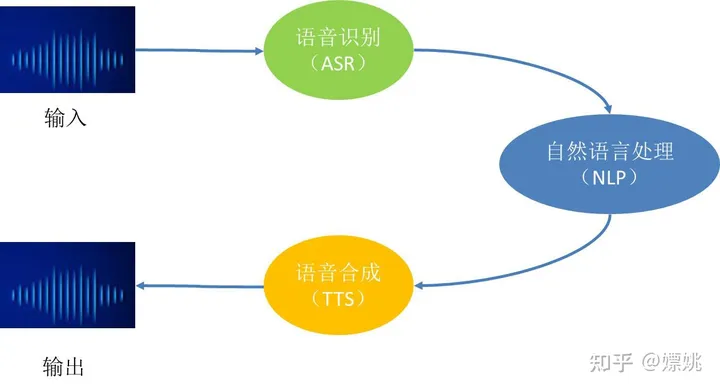
2 语音识别(ASR)
通常语音识别有两种方法:
“传统”的识别方法,一般采用隐马尔可夫模型(HMM) 基于深度神经网络的“端到端”方法。 两种方法都需要经过“输入—编码—解码—输出”的流程。
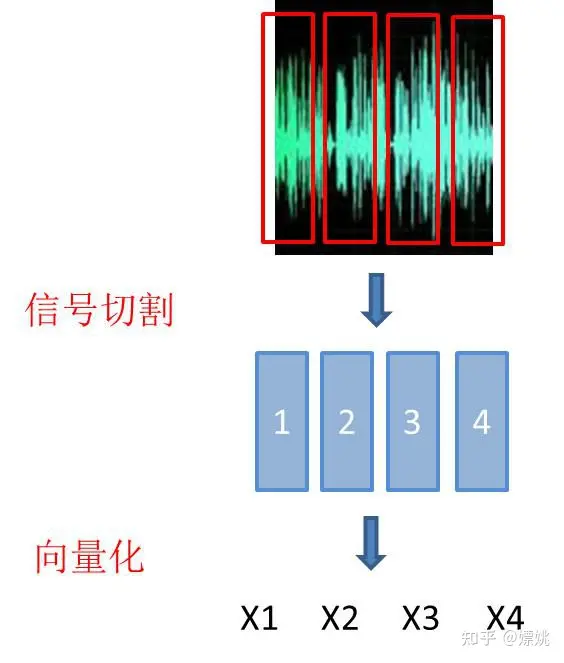
2.1 编码
编码就是把声音转化成机器能识别的样式,即用数字向量表示。
2.2 解码
解码就是把数字向量拼接文字的形式。
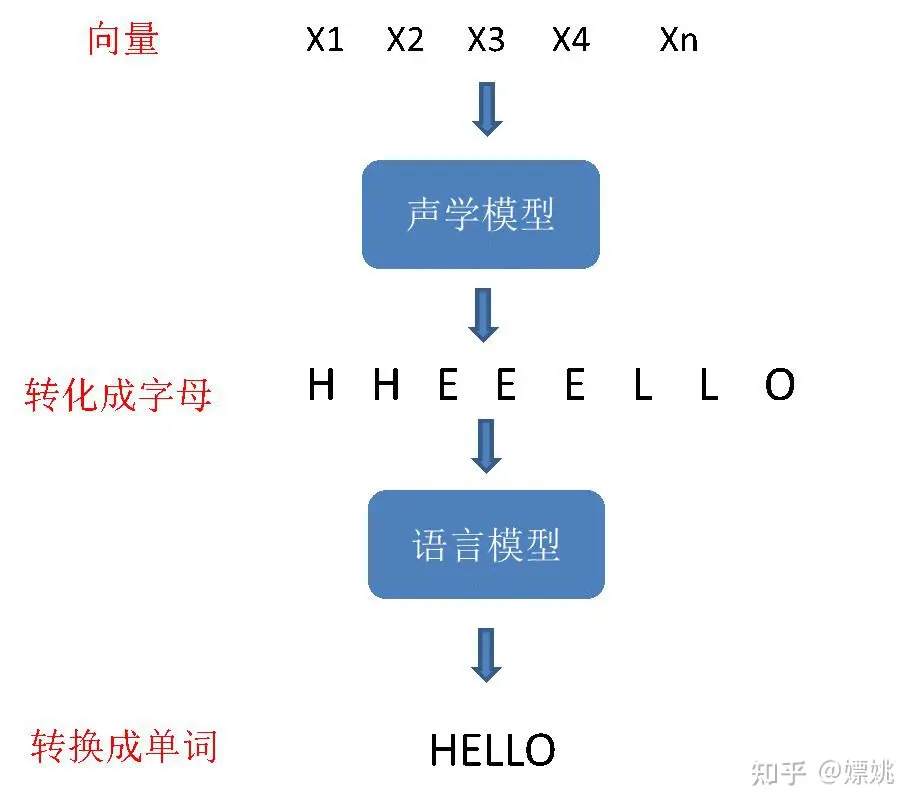
然后,把翻译出来的字母再经过语言模型,就可以组装成单词了。
当然声学模型和语言模型也是个神经网络,是通过大量的语音和语言数据来训练出来了,在这里就不展开讲了。
这里来个脑暴:
神经网络能不能做到,不需要编码和解码的过程,不需要声学和语言模型,直接把声音信号丢到神经网络里去训练,最后输出结果就是文字,具体中间过程是怎样的,让机器自己去学。如果这样能实现,我觉得很酷,看起来是不是真的很智能。
3 自然语言处理(NLP)
NLP是语音交互中最核心,也是最难的模块。
NLP主要涉及的技术有:文本预处理、词法分析、句法分析、语义理解、分词、文本分类、文本相似度处理、情感倾向分析、文本生成等等。但不局限于这些,涉及的技术比较多,且比较复杂。下面我们就挑几个主要的技术点简单聊下。
3.1 文本预处理
1)去噪声:
只要跟输出没有关系的我们就叫噪声,比如:空格、换行、斜杆等。
去噪声后,文本变得更加规范化,不会出现各种乱七八糟的符号,对于后续的处理非常重要。
2)词汇归一化
这个在处理英文文本时比较常用,如“play”,“player”,“played”,“plays” 和 ”playing”是“play”的多种表示形式。虽然他们的含义不一样,但是上下文中是相似的,可以把这些各种形式的单词归一化。
归一化是具有文本特征工程的关键步骤,因为它将高纬特征(N个不同特征)转化成低维空间。
3.2 词法分析
1)分词
分词就是把一个句子,切分成多个词汇。
比如:输入“明天深圳的天气怎样?”,这个句子就会被分成“明天/深圳/的/天气/怎样”。其中“明天”、“深圳”、“天气”就是这句话的关键词,通过关键词去匹配内容。
2)实体识别
实体提取:是指在一个文本中,提取出具体特定类别的实体,例如人名、地名、数值、专有名词等。
比如:输入“詹姆斯在NBA打了多少年”,其中“詹姆斯”就是实体词,计算机可能就可以通过当前的时间和詹姆斯加入NBA的时间给出他在NBA的球龄。
实体识别在信息检索、自动问答、知识图谱等领域运用的比较多,目的就是告诉计算机这个词是属于某类实体,有助于识别出用户意图。
3.3 文本分类
主要目的是为了将文档(文章)的主题进行分类,比如说是属于经济类、体育类、文学类等等。
解决文案分类问题,比较经典的算法是TF-IDF算法。
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
别说“NBA”这个在一篇文章中出现的次数比较多,但又很少在其他文章中出现,那这篇出现多次“NBA”这个词的文章很可能就是体育类文章。
3.4 文本相似度处理
文本相似度通常也叫文本距离,指的是两个文本之间的距离。文本距离越小,相似度越高;距离越大,相似度越低。
比如:用户输入“这件衣服多少钱”或者说“这件衣服怎么卖”,这都是很口语化的句子,那要怎么给用户返回“衣服价格”呢?就是根据文本相似度处理的。
需要我们计算出“多少钱”、“怎么卖”跟“价格”的相似度,然后根据相似度去匹配最佳答案。
应用场景:推荐、排序、智能客服以及自动阅卷等。解决之前只能靠关键词精准匹配问题,识别语义,扩大了应用的范围。
3.5 情感倾向分析
情感倾向分析,主要分为两大类:情感倾向分类、观点抽取。
1)情感倾向分类
情感倾向分类是识别文本的情感倾向,如:消极、积极、中性。
比如:“这家餐馆不错,服务态度好、价格便宜”,整个句子是积极的评价。
情感倾向分类对给用户打标签,给用户推荐内容或服务,有比较好的效果。
2)观点抽取
观点抽取是把句子中的观点抽取出来。
还是“这家餐馆不错、服务态度好,价格便宜”这个句子,其中“服务态度好”、“价格便宜”就是观点词。
观点抽取对建立服务或内容的评价体系,有重要的意义。
3.6 目前遇到的困难
1)语言不规范
虽然目前我们可以总结出一些通用的规则,但是自然语言真的太灵活了。同一个词在不同的场景可能表达多个意思, 不管是通过理解自然语言的规则,还是通过机器学习,都显得比较困难。
2)错别字

3)新词
在互联网高速发展的时代,网上每天都会产生大量的新词,我们如何快速地发现这些新词,并让机器理解,也是非常重要的。
4 语音合成(TTS)
实现TTS,目前比较成熟的有两种方法:“拼接法”和“参数法”。
4.1 拼接法
首先,要准备好大量的语音,这些音都是又基本的单位拼接成的(基本单位如音节、音素等),然后从已准备好的声音中,抽取出来合成目标声音。
优点:语音合成的质量比较高。 缺点:数据量要求很大,数据库里必须有足够全的“音”。
4.2 参数法
根据统计模型来产生每时每刻的语音参数(包括基频、共振峰频率等),然后把这些参数转化为波形。
优点:对数据的要求要小点。 缺点:质量比拼接法差一些。
4.3 其他方法
谷歌DeepMind提出的WaveNet方法,基于深度学习的语音合成模型,不会对语音信号进行参数化,使用神经网络直接在时域预测合成语音波形的每一个采样点。 Deep Voice 3采用一种新颖的用于语义合成的全卷积架构,可以用于非常大规模的录音数据集。 VoiceLoop是Facebook提出的一种新的TTS神经网络,它能将文本转换为在室外采样的声音中的语音,且该网络架构比现有的网络架构简单。